

















今回は、Jupyter Notebook上でMatplotlibを使って、ヒストグラムの基礎的な書き方を説明していきます。
まずはじめにヒストグラムについての説明ですが、Wikipediaには以下のように説明されています。
ヒストグラム(英語: histogram[1])とは、縦軸に度数、横軸に階級をとった統計グラフの一種で、データの分布状況を視覚的に認識するために主に統計学や数学、画像処理等で用いられる。柱図表[1]、度数分布図、柱状グラフともいう。
工業分野では、パレート図、チェックシート、管理図、特性要因図、層別法、散布図と並んで、品質管理のためのQC七つ道具として知られている。
(出典:Wikipedia)
そして、前提条件として、「Python」と「Jupyter Notebook」がインストールされている必要があります。まだインストールされていない方は、以下のリンクからぼくの別記事に移って、それぞれのインストールの方法を参照してください。
LINK:機械学習・深層学習の第一歩【Python】を実装しよう
LINK:Jupyter Notebookの使い方解説【Python学習・データ解析】
また、Matplotlibを使った2次元グラフの描き方の基礎をぼくの別記事で説明していますので、以下のリンクから参照して見てください。
LINK:【Jupyter Notebook】Matplotlibで2次元グラフを描こう【その1:折れ線グラフと散布図】
LINK:【Jupyter Notebook】Matplotlibで2次元グラフを描こう【その2:棒グラフ】
ヒストグラムの描き方

それでは、早速ヒストグラムの描き方を説明します。

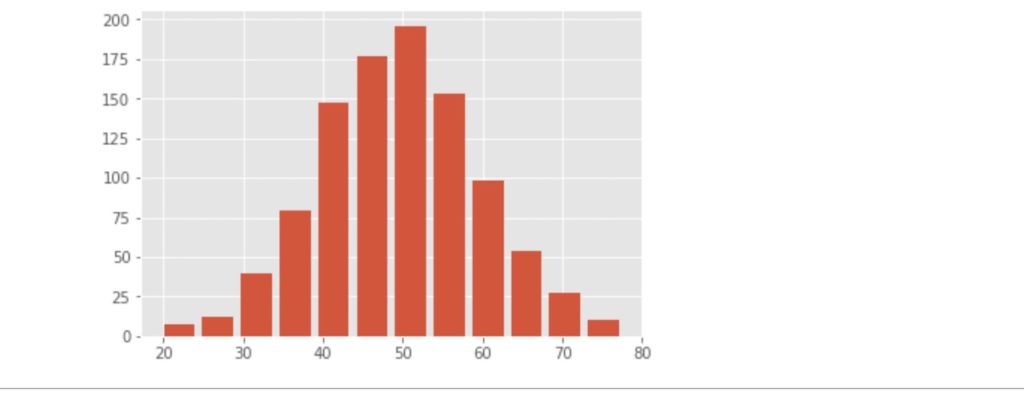
上記のスクショがヒストグラムを描くためのコードとその出力結果です。それでは、コードを簡単に解説します。
ライン1:「numpy」のインポート。numpyは今回乱数を発生させるために必要です。
ライン2:「matplotlib」のインポート。こればないと始まりません。(笑)
ライン3:コードの直下に表を表示させるマジックコマンドです。
ライン4:グラフのスタイルを変更します。(目盛り線を入れる。)
ライン6:変数 meanに平均値、50を代入。
ライン7:変数 SDに標準偏差、10を代入。
ライン8:乱数のシード値を0に設定。(毎回同じ乱数を発生させる。)
ライン9:平均50、標準偏差10、サンプル数1000の数字を発生させ、xに代入。
ライン11:figure()関数でFigureクラスのインスタンス作成。
ライン12:サブプロットの配置
ライン13:Axes.histメソッドにより、棒の幅、0.8、棒の数12で、Xのヒストグラムを作成。
ライン15:ヒストグラムの描写。
ぼくの別記事、2次元グラフを描こうの(その1)、(その2)を読まれた方なら、問題なくわかるところも念の為、解説しておきました。
よくわからない場合は、とりあえず上記のコードを写経(そのまま写す。)してみていただき、実行できることを確信した上で、色々と修正して、いじってみてください。そうしているうちに、理解が進むと思います。やはり、読むだけではなかなか実感できず、理解しづらいので、指と頭を使って学習されること強くお勧めします。
実際のデータを使ってヒストグラムを描いてみる

それでは、次に実際のデーターを使ってヒストグラムを描写してみましょう。ここでは、sklearnのトイデータセットのうち「ボストン市の住宅価格データ(Boston house prices dataset)」をダウンロードして使います。
ダウンロードのためのコードは以下の通りです。

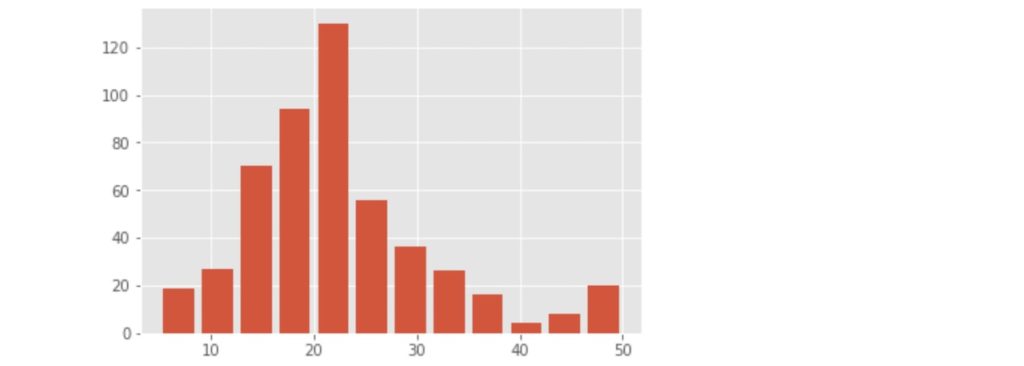
それでは、ボストン市の住宅価格データのうち住宅価格を使ってヒストグラムを描くコードとその表示結果は以下のようになります。

横向きのヒストグラムの描き方


横向きのヒストグラムを描写するには、ライン13にあるメソッドax.histの引数orientationにhorizontalを設定すると横向きのヒストグラムが描写できます。
累積ヒストグラムの描き方


累積ヒストグラムを描写するには、ライン13にあるメソッドax.histの引数cumulativeにTrueを設定する累積ヒストグラムが描写できます。
最後に

今回はmatplotlibを使って基礎的なヒストグラムの描写の仕方を説明いたしました。後ほど応用編として複数のヒストグラムを一つの表にまとめて表示する方法をご紹介いたします。ご期待ください。
最後までお付き合いいただき、ありがとうございました。それでは、さようなら。


コメント