
















ここでは、初めての機械学習【ライブラリーとデータの登録】まず、Pythonが実装されている必要があるので、まだ実装されていない方は、以下のリンクから別記事に移って、記事を参照しながらPythonをAnacondaを使ってインストールし実装してください。実際のコーディングは「Jupyter Notebook」というツールをブラウザー上で使って行っていきます。このツールはAnacondaを使ってPythonをインストールすると自動的にインストールされます。実際のコーディングは「Jupyter Notebook」というツールをブラウザー上で使って行っていきます。このツールはAnacondaを使ってPythonをインストールすると自動的にインストールされます。
ライブラリーの読み込み

まず、ライブラリーのインポートを行います。インポートするライブラリーは「scikit-learn」、「NumPy」、「SciPy」、「matplotlib」、「pandas」、「IPython」です。これらのライブラリーを以下のPythonのコマンドによってimportし、そのバージョンを見てみましょう。

記述したPythonのコードを実行するには、実行ボタンをクリックしても良いのですが、「Shift」+「Enter」のショートカットが便利です。実行すると以下のようになります。

データの読み込み

それでは、ゆりの花のデータセットをscikit-learnのdatasetモジュールから以下のコードによってダウンロードしiris_datasetという変数に代入しましょう。(iris(発音はアイリス)はユリという意味です。)

このデータセットには、いろいろな情報が含まれています。花の花弁とがく片のサイズ(長さと幅)のデータは「data」としてふくまれています。それではこの情報をよびたしてみましょう。

上記のコードを実行すると、以下のデータが表示されます。

実は、上記のデータは150個あります。上のデータはそのうちの始め5つを記述したものです。
それでは、品種のデータを呼び出してみましょう。データは「target」として含まれています。

このコードを実行すると以下の品種データを示す0から2までの数字が表示されます。

つぎに上記のtargetの0から2の数字が対応しているユリの品種の名前を呼び出してみましょう。品種の名前は「target_names」として含まれています。

このコードを実行すると以下の名前が表示されます。これは、「target」の0、1、2がそれぞれ'setosa' 'versicolor' 'virginica'に対応していることを示しています。

それではこのデータセットにどのような種類のデータが含まれているか、データの種類を呼び出してみましょう。

上記のコードを実行すると次の結果が表示されます。
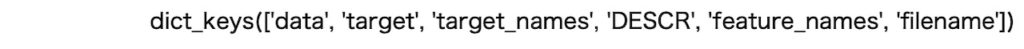
このデータには、data, target, target_name, DESCR, feature_namesとfilenameの6種類のデータが格納されています。それでは最後にDESCR(Descriptionの略)にはそのような情報が格納されているのかみて見ましょう。

このコードを実行すると、以下のような表示が見られます。


上記を見ていただけばわかるようにDESCRの情報はこの情報の概要的な説明をする情報です。
まとめ

それではいかがでしたでしょうか。機械学習の第1歩として、準備段階のPythonのライブラリーの読み込みとデータの呼び込みの方法をお話ししていきました。次は機械学習のK近傍法を使って実際の実装を行なっていきたいと思います。また、本記事はAndreas C. Muller氏とSarah Guido氏による「Introduction to Machine Learning with Python」を参考にしています。


コメント