


















ぼくの以前の記事の「その1」、「その2」の記事により、MNISTデータセットの読み込みならびに手書き文字のイメージをコンピュータが理解できる形に変換することを説明しました。
今回はそれらを元に、手書き文字のイメージがどの数字を示しているかを、コンピュータに判断させるアルゴリズムの構築を行います。
具体的にはTensorFlowをバックエンドとして使って、Kerasと言うライブラリーを使ってニューラルネットワークを作っています。それではあまり細かいことは気にせずに、実装していきましょう。
また、今回はこのシリーズの最終回ですので、以前説明したことも、さらっとおさらいも交えながらお話ししていきます。
MNISTデータセットの読み込み

これは過去記事「その1」でお話しした部分です。詳しいことを知りたい方は、「手書き文字認識の実装をしてみる。その1(MNISTデータセットの説明とダウンロード)」を読んでみて下さい。
2: from keras.datasets import mnist
3: (x_train, y_train), (x_test, y_test) = mnist.load_data()
4: x_train.shape, y_train.shape, x_test.shape, y_test.shape # ((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))
上記のコードの最後では、一応確認のため、読み込んだデータセットの「形」を確認のため出力しています。(コメント通りだと問題ないです。)
手書き文字のイメージをコンピュータが認識できる形に変換

これは過去記事「その2」で解説した部分です。
2 : from PIL import Image
3 : from sklearn import externals
4 : import matplotlib.pyplot as plt
5 : %matplotlib inline
6 : from PIL import Image
7 : import PIL.ImageOps
8 : #image size
9 : size = 28
10 : #image name
11 : test_image = "./T3.jpg"
12 : #convert image to gray scale
13 : image = Image.open(test_image).convert("L")
14 : #reverse image
15 : image = PIL.ImageOps.invert(image)
16 : #change image size
17 : image = image.resize((size, size))
18 : #make image flat
19 : test_data = [np.array(image).flatten()]
20 : #convert to np array
21 : test_data = np.array(test_data)
22 : test_data = test_data / 255
23 : #indicate image
24 : plt.imshow(test_data.reshape(size, size), cmap='Greys')
25 : plt.show()
上のコードでは、ルートディレクトリーに「T3.jpg」と言う手書き文字のイメージをセーブし、それをnumpy arrayに変換してtest_dataと言う変数に代入しています。また、最後の2行で変換後のイメージの表示をしています。
それでは、ぼくの過去記事その1、その2によりMNISTデータセットの読み込み、ならびに手書き文字のイメージをコンピュータが認識できる形に変換します。具体的には以下の通りです。

変換前
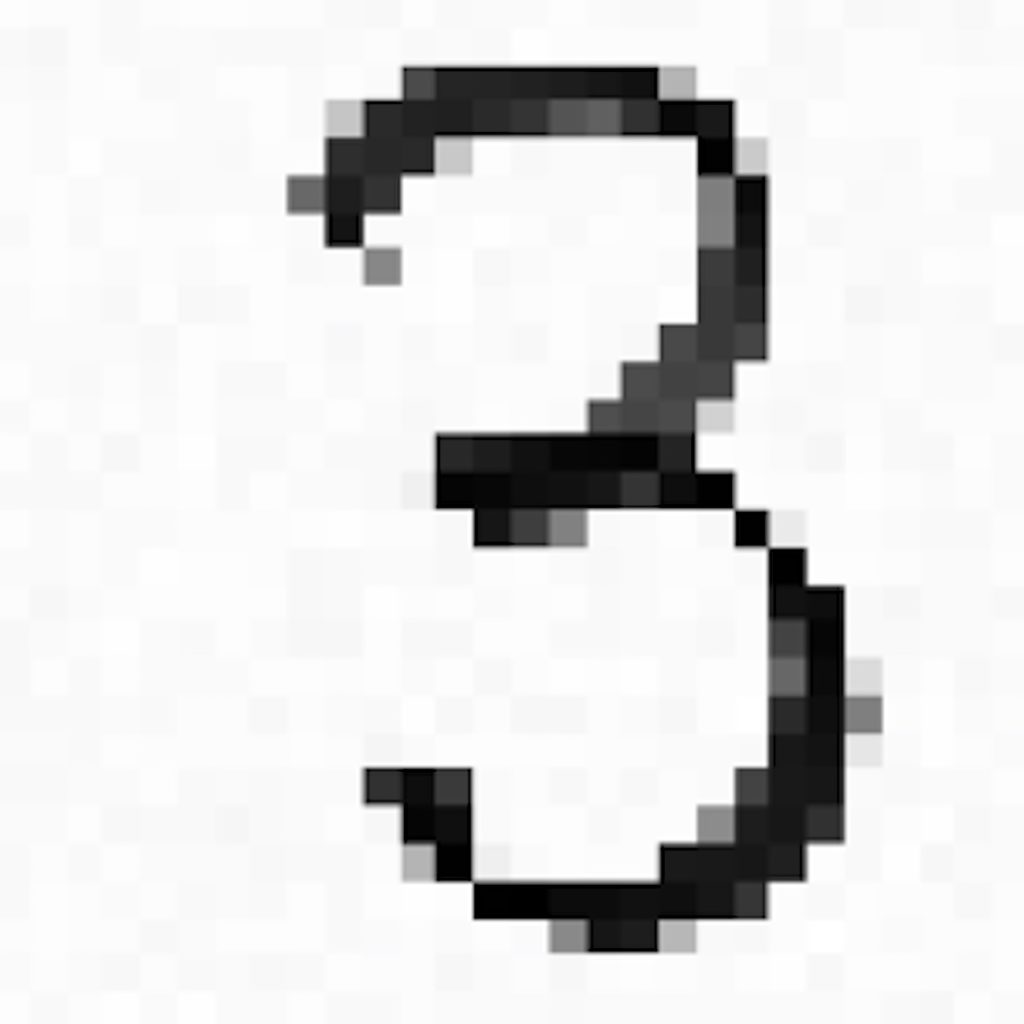
変換後
この例では、変換後のイメージの解像度をMNISTのデータセットに合わせて(合わさないと学習結果を使えない。)28x28にしていますが、これは上記コードの9行目のsizeを変更することにより調整できます。また、もとのイメージの解像度は任意で結構です。縦横の解像度を合わす必要もありません。
理解したデータをもとに数字を判別

それでは、本記事の本題のMNISTデータセットをもとにアルゴリズムを教育して、手書き文字のイメージを認識させる工程の説明に入ります。
ここではTensorFlowとKerasを使い実際にニューラルネットワークの構築を行います。
2 : from keras.layers import Dense, Activation
3 : model = Sequential()
4 : model.add(Dense(units=256, input_shape=(784,)))
5 : model.add(Activation('relu'))
6 : model.add(Dense(units=100))
7 : model.add(Activation('relu'))
8 : model.add(Dense(units=10))
9 : model.add(Activation('softmax'))
10 : model.summary(
次に以下のコードのよってモデルをコンパイルします。(行番号1から5)さらにバッチサイズ100、エポック数10で学習します。
2 : loss='categorical_crossentropy',
3 : optimizer='sgd',
4 : metrics=['accuracy']
5 : )
6 : model.fit(
7 : x_train, y_train,
8 : batch_size=100, epochs=10,
9 : validation_data=(x_test, y_test)
10 :
この後、学習部分を10回ほど繰り返すことにより、以下の表示のように学習データで99.22%、テストデータで97.83%の確率で正しい答えを導き出せるようになりました。

それでは、手書きの「3」のデータを構築したモデルに読ませて、判読させてみましょう。
2 : print(expect)

上記が構築したモデルに手書きの「3」のデータtest_dataを代入し、predictさせた結果です。これは、10個の要素から構成されていて、前から、0、1、2、であると推測される確率の確かさを示しています。
2 : print(expect[0][np.argmax(expect)])

それでの最も確率が高いと推測された番号は上記のように「3」でそれである確率は93.10825%と表示されています。
2 : for i in range(10):
3 : print(expect[0][i])
4 : total = expect[0][i] + total
5 : print(total)

また、最後にそのぞれの数字である場合の確率を表示してみると以上のようになります。上から順に、「0」である確率は、0.034...%、「1」である確率は0.34...%、「2」である確率は2.50...%となり、最後は10個のそれぞれの確率の合計です。(論理的には1にならなければいけないが、丸めているため、1の近似値になっています。)
まとめ

今回が連続3記事の最後のまとめ記事になります。簡単ではありますが、ニューラルネットワークを利用しての手書き文字認識の実装が皆さんお持ちのコンピュータ上で可能になりました。MNISTのデータセットではかなりの認識率を上げているのですが、実際にぼくの手書き文字の認識では、「8」と「9」を3と認識する傾向にありました。これ以外はほぼ問題なく認識出来たいました。これらは、学習データを追加することにより解決できると思います。
まずは実装することを目的とした為、Kerasなので説明は端折ってしまいましたが、それらの解説記事も後々書いていきたいと思います。
それでは最後までお付き合い、ありがとうございました。さようなら。
おすすめプログラミングスクール
テックキャンプ エンジニア転職
ビジネス系YouTuberとして著名なマコなり社長が社長を務める株式会社Divが運営するTECH CAMP。
やり切れる教材と就職までのサポートが大きな強めです。
また、受講の際には各自Macを準備する必要があります。(有料でレンタルあり)就職できなければ授業料返還の保証がありますが、39才以下との条件があります。ご注意ください。
費用は短期集中で一括払いで総額税抜648,000円、夜間・休日で848,000円と安くない費用になります。
コロナの影響で閉鎖していた教室もマスク着用などの条件付きで、全室、2020年11月2日より使用可能になりました。
眺めていても何も始まりません。これを機に、まずは以下のリンクから無料カウンセリングを受けられてみてはいかがでしょうか。



■教育について ・圧倒的コミット量と網羅性 テックキャンプ エンジニア転職は600時間をかけてフロント/サーバーサイド/インフラ全てを一通り学びます。
■サポート体制について ・学習環境 オンライン問わずメンターに質問し放題なため、途中で諦めてしまうことがありません。 ・専属のトレーナーの存在 トレーナーは毎週の学習計画の作成、日々の進捗確認、 キャリアアドバイザーへのフィードバックなど期間中は二人三脚となってサポートします。 ・専属のキャリアアドバイザー 毎週のキャリア面談、面接対策や履歴書の添削、企業提案など転職が決定するまでサポートし続けます。 また、企業に入社した後も半年間であれば無料でキャリア相談を受け付けています。
受講スタイル:通学またはオンライン
場所:東京(渋谷)、大阪、名古屋、福岡
価格:
入会金不要で月々21,200円(税込)から、一括は648,000円(税抜)(短期集中)
主な学習言語:HTML/CSS、JavaScriptRuby on Rails等
期間:短期集中で10週間、夜間・休日で6ヶ月


コメント