


















こんにちは、みゆきメダカです。今回は「人工知能」、「機械学習」、「深層学習」の意味(定義)について解説していきますね。新聞や雑誌なのでメディアで取り上げられない日は無いそれぞれの言葉ですが、案外、その意味は漠然としか理解されていないのでは無いでしょうか。そのため、それぞれの関係や、境目などを尋ねられると、返答に困ってしまいますよね、
それでは、まず概念の近い「機械学習」と「深層学習」についてお話し、そのあとそれらの関係を含めて、「人工知能」についてお話ししますね。
機械学習(Machine Learning)について

機械学習を簡単に言うと「プログラム(機械)自体が与えられたデータをもとに自ら学習する仕組み」です。それでは手書き文字の認識を例に取りながら説明します。
機械学習では無い手書き文字認識
初期の手書き文字認識システムとして有名なものに、日本のハガキの郵便番号読み取りシステムがあります。最初期のこのシステムは機械学習では無いシステムでした。
このシステムの文字認識の部分を簡単に説明すると、ハガキの郵便番号を書くための四角形のエリアの手書き文字を工学的に読み取り、細かい白色と黒色のマスからなる画像に変換します。(書かれている部分が黒のマス、そうで無いところが白のマスになります。)
機械学習とは「プログラム(機械)自体が与えられたデータを基に、自ら学習する仕組み」を指します。それでは、「自ら学習しない仕組み」とはどんなものでしょうか。自ら学習しない仕組みの例として、最初期の手書き郵便番号読み取り機があげられます。このシステムははがきの所定の位置(はがきに書かれた四角形の中またはその周辺)にかかれた手書きの数字を光学的に読み取り、それを碁盤の目を黒と白に塗り分けたイメージに変換(前処理)してそれが0から9までのどの数字に当たるのかを推測するものです。この前処理されたイメージをもとに数字を推測するところが肝になるのですが、この推測する基準を事前にルールとしてプログラマーがコンピュータに教える方法がプログラムが自ら学習しない仕組み(一般に「ルールベースシステム」と呼ばれることが多いです。)です。具体的には、イメージを左右に分離してそれぞれの黒の数が同じであれば「8」の確率が高いとか、イメージを縦に3分割して真ん中の黒の数が全体の70%以上であれば「1」の確率が高い、といったルールが数多くあり、1つの手書き文字に対して、どのルールが当てはまるのか検証します。その結果として、最終的に「3」である確率がもっとも判断された場合、システムはその手書き文字は「3」であるという判断を下すわけです。このシステムのメリットは、コンピュータが下した判断の根拠がはっきりとしていることです。デメリットはルール作りに膨大な労力が必要になることです。上記の例では0から9までの10個の数字に対するルール作りなのでイメージしやすいですが、これが、ひらがな、カタカナ、漢字、アルファベット、多言語の文字などに広がっていくと、そのルール作りが容易でないのは想像できると思います。また、プログラマーがルールを明確化できないとシステムの構築ができません。
機械学習での手書き文字認識
それでは「自ら学習しない仕組み」のイメージが湧いたところで、本題の「自ら学習する仕組み」にもどりましょう。大雑把に言って、「自ら学習する仕組み」つまり機械学習とは、元ネタと解答(上記の例では前処理されたイメージとそのイメージが表すべき数字)を与えれば、機械(プログラム)がその解を見つける方法を自分自身で作り出す(学習する)仕組みのことです。具体的には、状況(データの規模や解答の種類や数等)により、アルゴリズムとそれを特徴付けるパラメーターを決めてやり、一定程度以上の数量の元ネタとその解答(学習データとその確かさを検証するテストデータ)を与えてやれば、自動的に学習し(一般的にアルゴリズムが内包する変数を調整し)それ以降は、プログラマーの助け無しに、自動的に新しい元ネタに対する解答を導き出すものです。「自ら学習しない仕組み」と比べて、なんと素晴らしい仕組みでしょうか。本当にこんなことが可能なのでしょうか。もちろん可能です。それどころか、上記の手書き数字の認識であれば、「Python」とその付属ライブラリーである「scikit-learn」を使えば、驚くほど簡単にみなさんお持ちのコンピュータ上で行うことができます。必要な元ネタとその解答もすでに準備されています。(もちろん、みなさんが各自で作られることも可能です。)機械学習のメリットとデメリットですが、まずメリットは何といっても、前段取り(データの取得ならびにそれらに対する前処理及び、適切なアリゴリズムの選択とそのパラメーターの設定)をしてやれば、機械(プログラム)が自動的に判断に必要なルールを決めてくれることです。デメリットは場合によっては、膨大な量のデータの集積が必要になることと、システム自体を構築したプログラマー自体でも結果の判断根拠が判らなくなることがある点です。
深層学習(Deep Learning)について

機械学習のイメージが何となくつかめたでしょうか。それでは次の深層学習の説明です。結論を先に言うと深層学習(Deep Learning)は機械学習の一種です。機械学習のアルゴリズムは数多くあるのですが、その中の一つにニューラルネットワークと呼ばれるアルゴリズムがあります。よく人間の脳の仕組みを模したものと言われるのですが、深層学習とはこのニューラルネットワークでその中の層(実際には中間層)を数多く重ねた形のものを指します。中間層を数多く持つことで、複雑な問題を解いたり、正解率を上げたりすることが可能になるといわれています。また、その代償として、莫大なコンピュータパワーが必要になったり、結果が出るまでに長時間を要したりします。
国際的に有名な画像の認識性能を競うコンペ(2012年の人工知能の競技会(ILSVRC))でヒルトン教授率いるトロント大学が深層学習を用いて他を大きく引き離して圧勝したことにより、深層学習は一躍脚光を集めるようになりました。その後には、他の大学もトロント大学に追随して深層学習の考えを取り入れ、近年ではほとんどの大学がこの種のコンペでは深層学習を取り入れています。少なくとも、現時点においては最も注目されている機械学習のアルゴリズムです。
人工知能(AI Artificial Intelligence)について

それでは、最後に残った「人工知能」についてお話していきましょう。人工知能はこれまでお話した「機械学習」や「深層学習」と異なり、みんなが納得できる定義がまだ確立されていません。その理由は、理解するには難解な「知能(Intelligence)」という言葉を名前の一部にもっているからでしょう。つまり人工的な知能である「人工知能」を定義するのならば、その前に「知能」そのものに対する定義が必要であるといった理屈です。
それでは「知能」とは何なのでしょうか。我々の多くが知能に関して共通の認識として共有できる数少ない考え方の一つとして、生物として最も進化した我々「人類において健全な個体は覚醒している間は少なくとも「知能」を持っている」と言われています。この考えに異を唱える人はごく少数なのではないでしょうか。
それでは、健全な人類が覚醒している間は知能を有することを前提条件として、次に「知能」と「知能でないもの」の境界を探っていきましょう。
具体的な手法として、人間以外の動物が「知能」をもっているか考えていきます。身近な高等動物として犬はどうでしょう。犬は知能をもっているか。この問いに対する答えは、回答者の心情やその人がどのような立場で回答するか(例えば、動物学者としてか、哲学者としてか、企業家としてか)によって変わってくると思います。つまり、知能の定義には一定の幅(グレーゾーン)が存在するということです。従って、狭義のAI、広義のAIと言う分類や、強いAI、弱いAIと言った分類がされるようになります。
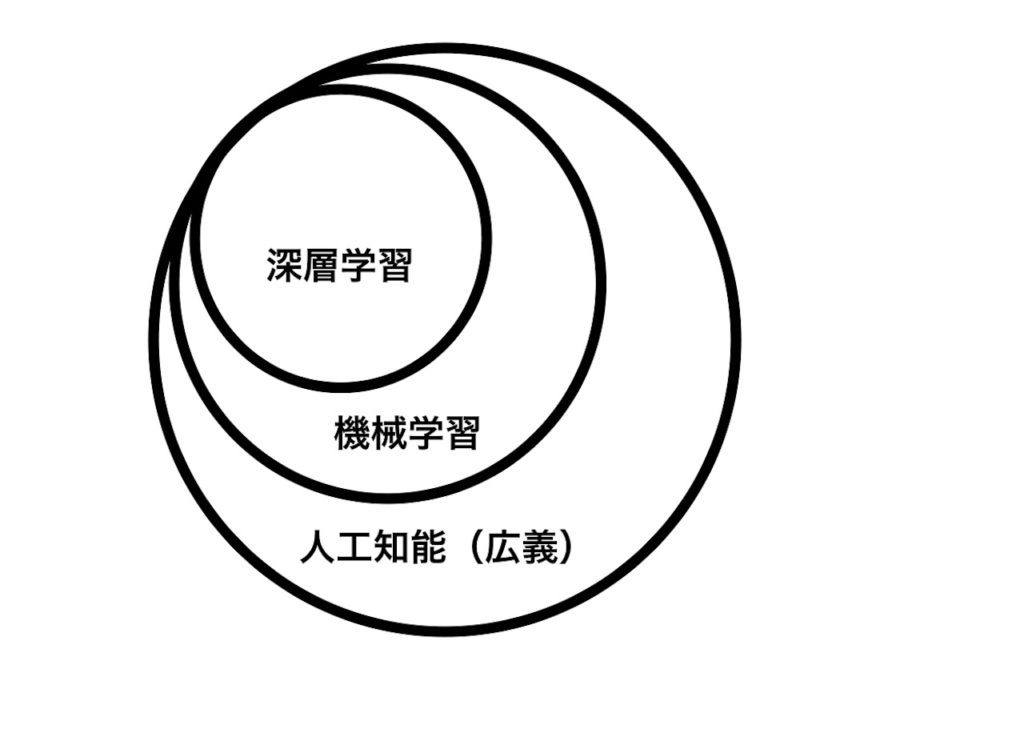
一般的に言われている広義の人工知能の場合は上のベン図に示したように、機械学習を含んだかなり大きなものの定義として使われています。一方、専門家の中にも、現在人工知能はまだ、完成されていないと言う主張をされている方や、人工知能は永遠に実現されないと言った立場をとる方々もいます。
まとめ

いかがだったでしょうか。3つの言葉の意味、理解していただけたでしょうか。それでは次回から実際の実装方法についてお話ししていきますね。
それでは最後までお付き合い頂きありがとうございました。さようなら。


コメント