

















この記事は、手書き文字を(実際には0から9までの10個の一桁の数字)を機械学習の手法を用いてコンピューターに認識させる方法を解説していく3連の記事の1番目です。
今回は1番目の記事として、今回使用するMNISTデータセットの説明とそのダウンロードの方法をお話しします。
2番目の記事は「手書き文字イメージをコンピュータが理解できる形に変換」、3番目の記事は「MNISTデータセットをもとに学習したアルゴリズムを用いて手書き文字の判別」を説明する予定です。
この手の手書き文字認識は、日本では1960年代に東芝が開発した郵便物の郵便番号の読み取り機が有名です。当時は現在のように機械学習の手法ではなく、それぞれの文字の認識方法を個別にルールを定めて文字の認識を行なっていました。機械学習の手法では、教師あり学習の方法で解答のあるデータセットを与える事により、自動的にアルゴリズムが認識の方法を学習します。
1960年代には国を代表する企業が注力して実現させたものとほぼ同等の機能が、今日では個人用のコンピュータと機械学習の手法により精度の差はあれ、実装できる事に技術の進歩を感じますね。
使用する環境は、MacでPythonをJupyter Notebookを使って動かします。また、Windowsでも問題はないはずですおおおお。
また教師ありデータのデータセットとしては、前述の通り、有名はMNISTデータセットを使用します。
MNISTデータセットの説明

それではMNISTデータセットのダウンロードですが、その前に少し、このデータセットについて説明させてください。MNISTはModified National Institute of Standrads and Technologyの略でアメリカの商務省傘下のアメリカ国立標準技術研究所という機関(National Institute of Standrads and Technology)が作ったデータセットの"Remix、Modified"版です。
実際には、60000個のトレーニングデータと10000個のテストデータから構成されており、それぞれには28x28ピクセルでそれぞれのピクセルが256段階(0から255)の濃淡を持ったモノクロ文字イメージをデータとして、また、そのイメージが表す文字(0から9までの一桁の数字)をラベルとして持っています。
実際のデータには28x28のサイズのタプルに各要素として0から255までの整数が入っています。
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]
ーーーーーーーーーー(省略)ーーーーーーーーーー
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
上記のタプルをイメージ化したのを以下に示します。
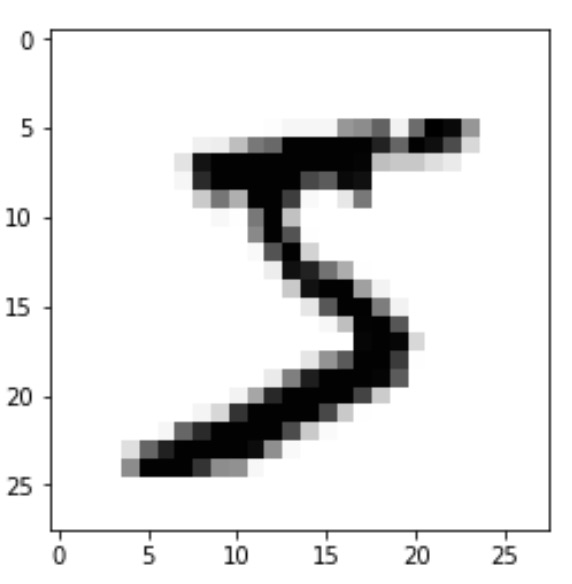
また、これのラベルは”5”です。
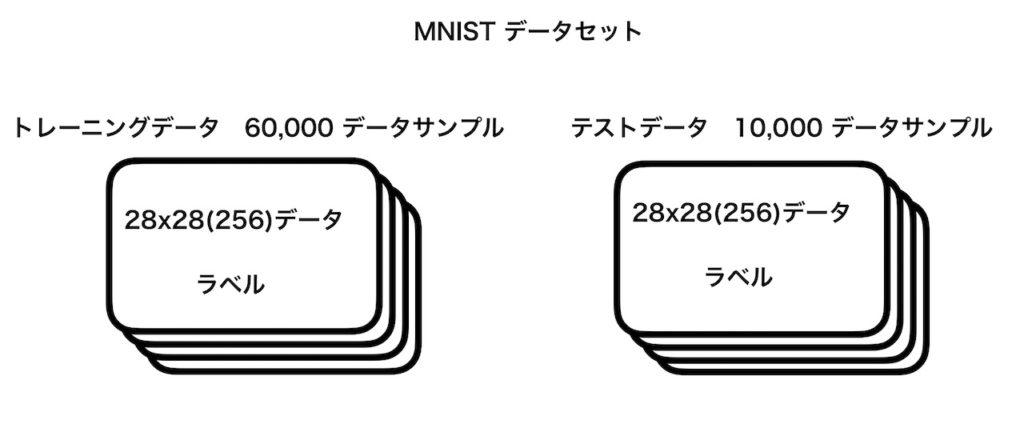
MNISTでは28x28のサイズのタプルをデータとしてまた、1桁の整数(上の例では”5”)をラベルとして一つの要素を形成し、データセット全体としてこれらのデータサンプルを60,000 (トレーニングデータ)+ 10,000 (テストデータ)= 70,000個有しています。以下にこのイメージ図を示します。
ここで注意したいのが、SKlearnのデータセットにも同じようなデータセット(Degits datasets:トイデータセット)がありますが、こちらのサイズはかなり小さく、文字のピクセル数は8X8で、データサンプル数も合計1,797個となります。混用しないようにしましょう。
MNISTデータセットのダウンロード

それでは、ダウンロードの仕方を説明します。数種類方法はあるのですが、ぼくが知る限りこれから説明する方法が、最も確実で簡単だと思います。
初めに「tensorflow」と「keras」をinstallする必要があります。ターミナルから以下のコマンドを入力して実行して下さい。ターミナルて何?と言う方は、以下のぼくの別記事へのリンクからターミナルの使い方の解説記事を読んでみて下さい。
【Mac】ターミナルの使い方の初歩・よくわからん黒いやつ【初心者向け】
|
1 |
pip3 install tensorflow |
エンターキーを押すとインストールの状況を示すテキストが長々と現れて最後に「Successfully installed .........」と表示が出ればtensorflowのインストールは完了です。次は「keras」です。
|
1 |
pip3 install keras |
この後、エンターキーを押すとtensorflowの時と同じように長々とテキストが現れて、最後に「Successfully installed .........」と表示があればインストール完了です。
この後はJupyter Notebookからのコーディングになります。
|
1 2 3 4 |
from keras import backend as K from keras.datasets import mnist (train_data, train_label), (test_data, test_label) = mnist.load_data() |
上記のコードではKerasのMNISTデータセットからダウンロードを行なっています。その結果が「train_data」、「train_label」、「test_data」、「test_label」のそれぞれの変数に代入されています。
MNISTデータセットのセーブとロード

それでは最後にダウンロードしたデータセットを再度使用するために、セーブ・ロードする方法を説明します。
|
1 2 3 4 5 6 |
from sklearn import externals externals.joblib.dump(train_data, "TRAIN_DATA") externals.joblib.dump(train_label, "TRAIN_LABEL") externals.joblib.dump(test_data, "TEST_DATA") externals.joblib.dump(test_label, "TEST_LABEL") |
上記のコードでダウンロードしたMNISTデータセットをデータの種類ごとにセーブします。
|
1 2 3 4 5 6 |
from sklearn import externals train_data_1 = externals.joblib.load("TRAIN_DATA") train_label_1 = externals.joblib.load("TRAIN_LABEL") test_data_1 = externals.joblib.load("TEST_DATA") test_label_1 = externals.joblib.load("TEST_LABEL") |
続いて、上記のコードでセーブしたデータをロード(読み込み)することができます。また、カレントデレクトリーに大文字のファイル(TRAIN_DATAなど合計4つ)が作成されているはずなので、念の為確認してみてください。
最後に
今回は機械学習による文字認識実装のための第一弾として、MNISTデータセットの解説・ダウンロード・セーブおよびロードの方法を解説してきました。今後は第2弾として、手書き文字のイメージをMNISTのデータと同じように28x28のタプルの変換する方法を説明する記事。第3弾としてそれらをもとに手書き文字を認識するアルゴリズムを実装する方法を説明する記事を更新していきます。
それでは最後まで、お付き合いありがとうございました。さようなら。


コメント