


















sklearnの中には、機械学習やデータ解析に使えるデータセットがいくつかロードして使えるように準備されています。今回はその中で、比較的小さなデータセットである「トイデータセット」と説明します。
それより大きく、実データに近い「実世界データセット」と都合の良いデータセットを生成する「データセットの生成」については後日、別記事で説明する予定です。
トイデータセットについて

sklearnには、7つのトイデータセットと言われる外部のwebからのファイルのダウンロードを必要とせず入手できるデータセットがあります。これらのデータセットは前述のように比較的小さく、手軽に各種のアルゴリズムの振る舞いを確認するのに便利です。また、
これらのうち、アヤメのデータセットのように、機械学習の入門書には常連のデータセットもあり、みなさんの中にはよくご存知の方も多いのではないでしょうか。また、これらのデータセットは既存のアルゴリズムを自分で修正した場合や、独自のアルゴリズムの検証に有益です。
現実的な事象を対象にした場合のシュミレーション目的での使用にはデータ量が少なすぎて適さない場合があります。その場合は、別途用意されている実世界データセットの使用や、用途に適したデータセットを作られることをお勧めします。
- アヤメの品種データセット(Iris plants datasets)
- ボストン市の地区別住宅価格データセット (Boston house prices datasets)
- 糖尿病患者の診療データセット (Diabetes datasets)
- 数字の手書き文字データセット (Digits datasets)
- 生理学的特徴と運動能力の関係についてのデータセット (Linnerrud datasets)
- ワインの本質データセット (Wine recognition datasets)
- 乳がんのデータセット (Breast cancer wisconsin datasets)
アヤメの品種データセット(Iris plants dataset)
概要
アヤメのデータセットは、よく機械学習の一番初めに使われるデータセットです。アヤメの3品種(Setosa, Versicolor and Virginica)の花に関する萼片の長さ、萼片の幅、花びらの長さの4つの特徴量を持っています。
- データサンプル数:150
- 特徴量の数:4 + 1
- 用途:分類
各特徴の構成
- 萼片の長さ(cm) sepal length (cm)
- 萼片の幅(cm) sepal width (cm)
- 花びらの長さ(cm)petal length (cm)
- 花びらの幅(cm) petal width (cm)
読み込み方法とデータセットの中身
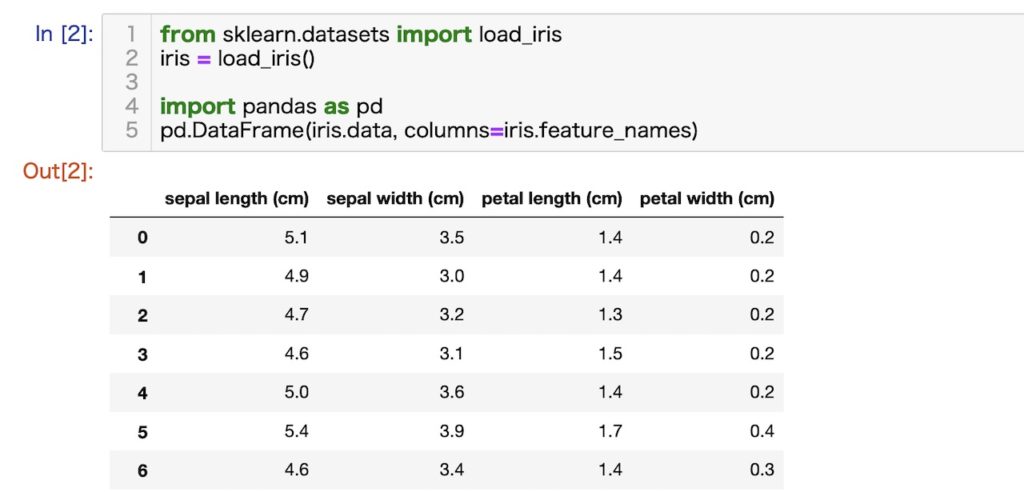
(省略)

ボストン市の地区別住宅価格データセット (Boston house prices dataset)
概略
このデータセットはボストン市郊外の特別の住宅価格のデータセットです。特徴量数が13と多いです。
- データサンプル数:506
- 特徴量数:13 + 1
- 用途:回帰
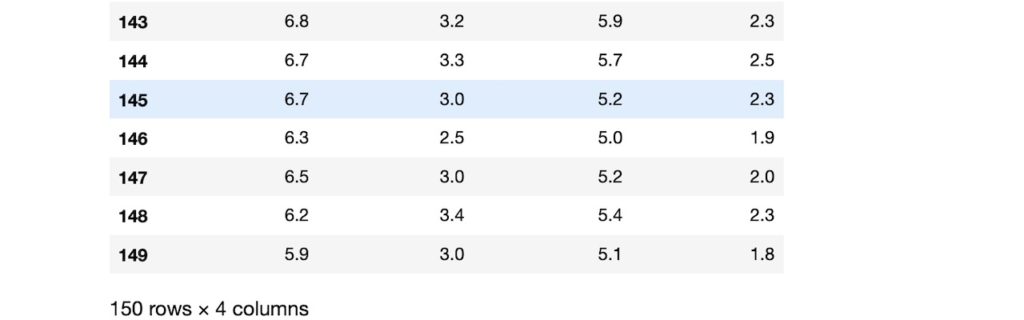
各特徴の構成
- CRIM 人口1人当たりの犯罪発生率
- ZN 25,000平方フィート以上の居住区画の占める割合
- INDUS 小売業以外の商業が占める面積の割合
- CHAS チャールズ川からの距離による変数(1=周辺、0=遠い)
- NOX NOXの濃度
- RM 住居の平均部屋数
- AGE 1940年よりも苗に建てられた住居の割合
- DIS 5つのボストン市の雇用施設からの距離
- RAD 高速道路へのアクセスのしやすさ
- TAX $10,000ドル当たりの不動産税率の統計
- PTRATIO 地区毎の児童と教師の割合
- B 地区毎の黒人の比率
- LSTAT 給与の低い職業に従事する人の割合(%)
読み込み方法とデータセットの中身
(省略)


(省略)

糖尿病患者の診療データセット (Diabetes datasets)
概略
442人の糖尿病患者の検査結果データとその1年後の糖尿病疾患の進行状況についてのデータセットです。
- データサンプル数:442
- 特徴量数:10 + 1
- 用途:回帰
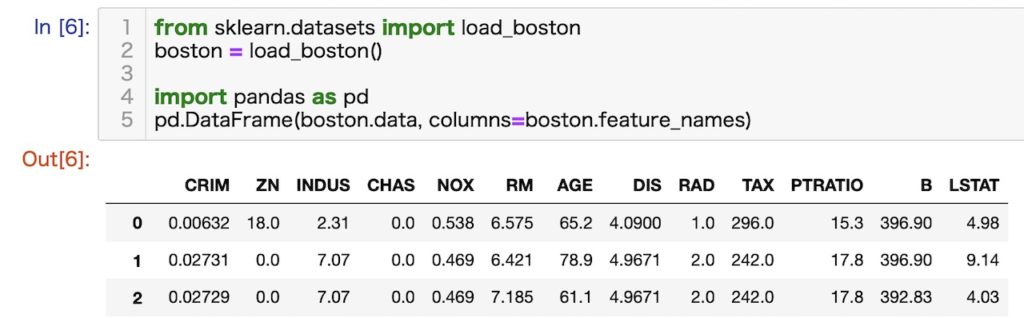
各特徴の構成
- age 年齢
- sex 性別
- bmi BMI
- map 平均血圧
- tc 血清の成分その1
- ldl 血清の成分その2
- hdl 血清の成分その3
- tch 血清の成分その4
- ltg 血清の成分その5
- glu 血清の成分その6
読み込み方法とデータセットの中身
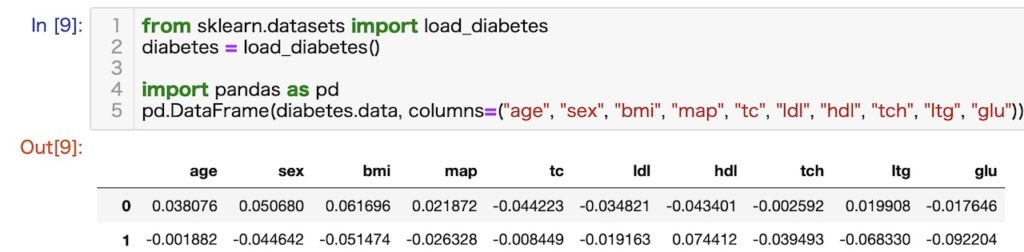
(省略)


(省略)

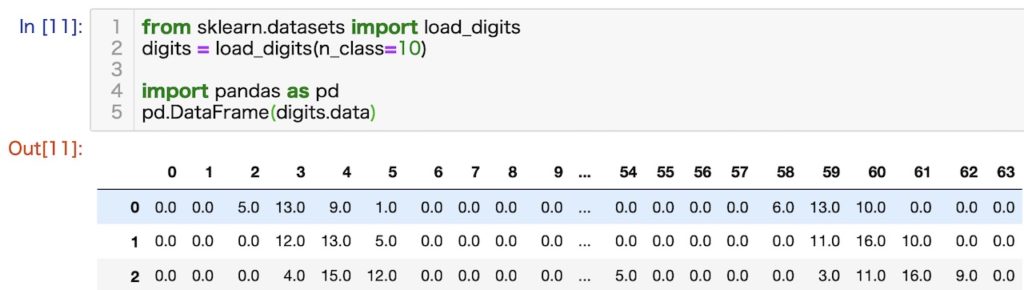
数字の手書き文字データセット (Digits datasets)
概略
0から9の10種類の手書きの数字を8x8の画素に分解表示したデータセットです。アヤメのデータセットと並んで有名なデータセットです。
- データサンプル数:1797
- 特徴量数:64
- 用途:他クラス分類
読み込み方法とデータセットの中身
(省略)


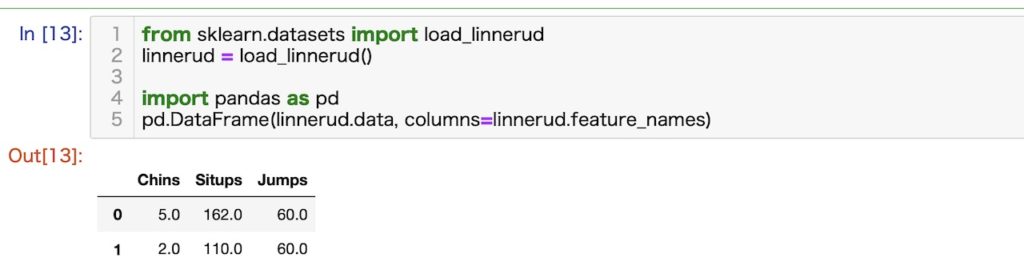
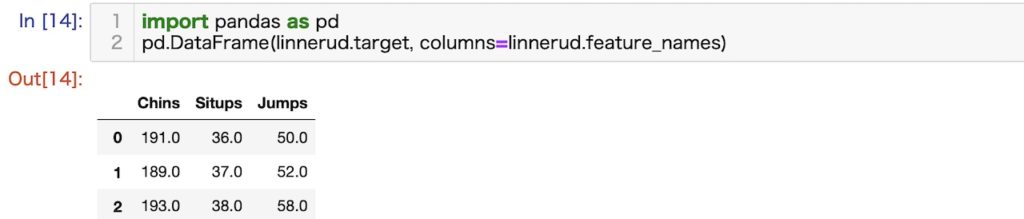
生理学的特徴と運動能力の関係についてのデータセット (Linnerrud datasets)
概略
20人の成人男性に関するフィットネスクラブで測定した3つの生理学的特徴と3つの運動能力の関係を示したデータセットです。
- データサンプル数:20
- 特徴量数:3 + 3
- 用途:多変数解析
各特徴の構成
- Weight 体重
- Wast 胸囲
- Pulse 脈拍
- Chins 懸垂の回数
- Situps 腹筋の回数
- Jumps 跳躍
読み込み方法とデータセットの中身
(省略)

(省略)

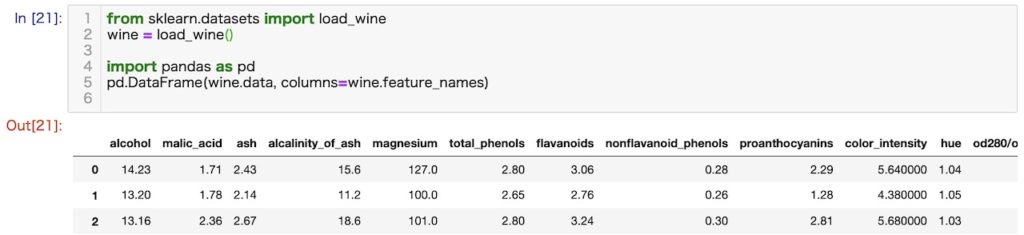
ワインの本質データセット (Wine recognition datasets)
概略
11種類のワインの成分とワインの専門家によるワインの品質評価を含んだデータセットです。
- データサンプル数:178
- 特徴量数:13
- 用途:分類
各特徴の構成
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
読み込み方法とデータセットの中身(データの列一部省略)
(省略)


(省略)

乳がんのデータセット (Breast cancer wisconsin datasets)
概要
乳がんの診断データを含んだデータセットです。各サンプルは30種類の腫瘍の特徴量と腫瘍が良性か悪性かの診断結果を含んでいます。
- データサンプル数:569
- 特徴量数:30 + 2(クラス)
- 用途:分類
各特徴の構成
- radius (mean):
- texture (mean):
- perimeter (mean):
- area (mean):
- smoothness (mean):
- compactness (mean):
- concavity (mean):
- concave points (mean):
- symmetry (mean):
- fractal dimension (mean):
- radius (standard error):
- texture (standard error):
- perimeter (standard error):
- area (standard error):
- smoothness (standard error):
- compactness (standard error):
- concavity (standard error):
- concave points (standard error):
- symmetry (standard error):
- fractal dimension (standard error):
- radius (worst):
- texture (worst):
- perimeter (worst):
- area (worst):
- smoothness (worst):
- compactness (worst):
- concavity (worst):
- concave points (worst):
- symmetry (worst):
- fractal dimension (worst):
読み込み方法とデータセットの中身(データの列一部省略)
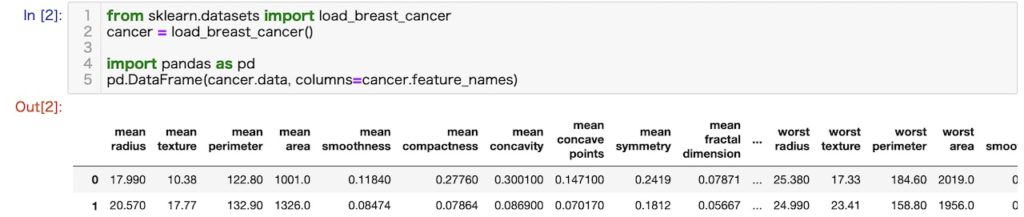
(省略)


まとめ
どれもいろいろなアルゴリズムの振る舞いを調べる上で有益なデータセットです。インポートの仕方とそれぞれのデータセットの特徴をつかんで、活用して下さい。
それでは、最後までお付き合いありがとうございました。さようなら。


コメント